Lux: Getting Started (Demo with Simulated Data)#
In this tutorial, we will demonstrate how to define a Lux model with two outputs using the LuxModel class. We will use simulated data, but the outputs are meant to loosely represent (1) stellar labels, like element abundances, stellar parameters, etc., and (2) stellar spectra (fluxes) on a wavelength-aligned grid of pixels. For the model, we will use a bi-linear structure in which both outputs are generated as linear transformations of a latent representation of each star. We will use a latent dimensionality that is larger than the number of stellar labels but much smaller than the number of pixels in the spectra.
We will start with some standard imports and set up the simulated data.
import jax
import jax.numpy as jnp
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import numpyro
import numpyro.distributions as dist
from numpyro.distributions.constraints import real
import pollux as plx
from pollux.models.transforms import LinearTransform
jax.config.update("jax_enable_x64", True)
%matplotlib inline
Generating simulated data#
We will generate data for 2048 stars, with a latent dimensionality of 8, but only 2 labels and 128 pixels in the spectra. We will define the linear transformations that generate the simulated labels and spectra to have some strict structure: the first 2 latent dimensions will be used to generate the labels, and will correlate with the strength of Gaussian “spectral lines” in the simulated spectra. This is purely for demonstration purposes, and we could instead have used random linear transformations (e.g., with all elements of the transform matrices drawn from a Normal or uniform distribution).
from helpers import make_simulated_linear_data
n_stars = 2048 # number of simulated stars to generate in the train and test sets
n_latents = 8 # size of the latent vector per star
n_labels = 2 # number of labels to generate per star
n_flux = 128 # number of spectral flux pixels per star
rng = np.random.default_rng(seed=8675309)
A = np.zeros((n_labels, n_latents))
A[0, 0] = 1.0
A[1, 1] = 1.0
B = rng.normal(scale=0.1, size=(n_flux, n_latents))
B[:, 0] = B[:, 0] + 4 * np.exp(-0.5 * (np.arange(n_flux) - n_flux / 2) ** 2 / 5**2)
B[:, 1] = B[:, 1] + 2 * np.exp(-0.5 * (np.arange(n_flux) - n_flux / 4) ** 2 / 3**2)
data, truth = make_simulated_linear_data(
n_stars=n_stars,
n_latents=n_latents,
n_flux=n_flux,
n_labels=n_labels,
A=A,
B=B,
rng=rng,
)
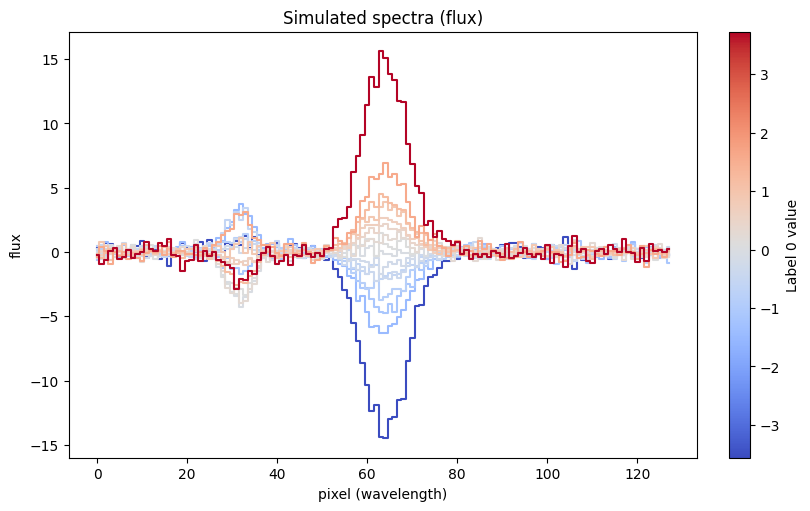
The data have simulated uncertainties, which the pollux.models.LuxModel will use to define the likelihoods for the labels and spectra. Here are a few examples of the simulated spectra, ordered by (and colored by) the value of the first (0th index) label:
cmap = plt.get_cmap("coolwarm")
norm = mpl.colors.Normalize(
vmin=data["label"][:, 0].min(), vmax=data["label"][:, 0].max()
)
fig, ax = plt.subplots(figsize=(8, 5), layout="constrained")
idx = np.argsort(data["label"][:, 0])
for i in np.linspace(0, len(idx) - 1, 16).astype(int):
ax.plot(
data["flux"][idx[i]],
marker="",
drawstyle="steps-mid",
color=cmap(norm(data["label"][idx[i], 0])),
)
ax.set(xlabel="pixel (wavelength)", ylabel="flux", title="Simulated spectra (flux)")
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
cb = fig.colorbar(sm, ax=ax)
cb.set_label("Label 0 value")
To use this data with the LuxModel, we will need to define a PolluxData instance. This object acts as a container for the data and uncertainties, and also provides a mechanism to define “pre-processors” for the data. In this case, we will define pre-processors that normalize the labels and spectra to have zero mean and unit variance:
all_data = plx.data.PolluxData(
flux=plx.data.OutputData(
data["flux"],
err=data["flux_err"],
preprocessor=plx.data.ShiftScalePreprocessor.from_data(data["flux"]),
),
label=plx.data.OutputData(
data["label"],
err=data["label_err"],
preprocessor=plx.data.ShiftScalePreprocessor.from_data(data["label"]),
),
)
preprocessed_data = all_data.preprocess()
For this example, we will use the Lux model in a “supervised” or “train and apply” mode, in which we will train the model on a subset of the data and then apply it to the remaining data. We will use the first 1024 stars for training and the remaining 1024 stars for testing (since they are not ordered in any way):
train_data = preprocessed_data[: n_stars // 2]
test_data = preprocessed_data[n_stars // 2 :]
len(train_data), len(test_data)
(1024, 1024)
Constructing the Lux model#
We create a Lux model by first defining a LuxModel instance with a specified latent dimensionality. In this case, we know that the data were generated with a latent dimensionality of 8, so we will use that value in this example:
model = plx.LuxModel(latent_size=8)
We then have to tell the model about the outputs (i.e. predict data) using the register_output() method. For this method, we specify an output name and a transform that specifies how the output will be generated from the latent representation. We currently have a few built-in transforms (LinearTransform, AffineTransform, and QuadraticTransform), but plan to add more in the future. We note that it is possible to define custom transforms by subclassing the AbstractTransform class.
In this example, we will use linear transformations (using LinearTransform) for both outputs of our demo model. We can define the transforms by, at minimum, specifying the output dimensionality for each output. In this case, the output names should match the names of the blocks in the data:
print(all_data.keys())
model.register_output("label", LinearTransform(output_size=n_labels))
model.register_output("flux", LinearTransform(output_size=n_flux))
dict_keys(['flux', 'label'])
With no other arguments, the LinearTransform will generate a linear transformation matrix and use a Normal prior for the elements of the matrix with zero mean and unit variance. When optimizing, this is equivalent to placing an L2 regularization on the elements of the matrix. However, we can also override the default prior by specifying the param_priors argument to the LinearTransform initializer. This argument should be a dictionary with keys that match the names of the parameters in the transform and values that are instances of Distribution. For the LinearTransform, the parameter name is A and this represents the matrix that maps latent dimensionality to output dimensionality.
For example, if we wanted to use an L2 regularization with a different regularization strength alpha, we could specify a different prior for A:
alpha = 100.0
trans = LinearTransform(
output_size=n_labels, param_priors={"A": dist.Normal(0.0, jnp.sqrt(1 / alpha))}
)
Or, to disable regularization entirely, we could instead specify a ImproperUniform prior:
trans = LinearTransform(
output_size=n_labels, param_priors={"A": dist.ImproperUniform(real, (), ())}
)
For this example, we will proceed with the default priors for the linear transformation matrix elements.
As an initial test of the using the model, we will generate random values for latent vectors and the linear transform parameters and use the predict_outputs() method to generate predictions for the labels and spectra. These predictions will be meaningless in practice, because we have not yet optimized the parameters of the model, but they will demonstrate the structure of the model:
rngs = jax.random.split(jax.random.PRNGKey(42), 3)
# For this demo, we'll generate outputs for 10 objects
latents = jax.random.normal(rngs[0], shape=(10, model.latent_size))
pars = {
"label": {"A": jax.random.normal(rngs[1], shape=(n_labels, model.latent_size))},
"flux": {"A": jax.random.normal(rngs[2], shape=(n_flux, model.latent_size))},
}
outputs = model.predict_outputs(latents, pars)
outputs["label"].shape, outputs["flux"].shape
((10, 2), (10, 128))
Later, once we have optimized the parameters of the model, we can use this method to generate predictions for new or held-out data, or to validate the model.
Optimizing the model with training data (i.e. training the model)#
As mentioned above, in this demonstration, we will use the first 1024 stars for training the model and the remaining 1024 stars for testing the model performance. We will optimize the model parameters using the training data and then evaluate the model on the test data and compare with the true values.
We will use the optimize() method to optimize the model parameters, which uses numpyro’s MAP estimation functionality under the hood. This model has a large number of parameters: the elements of each linear transformation matrix — (2, 8) and (128, 8) in shape — along with the latent vectors for each star. We therefore need to use an optimizer that can handle a large number of parameters. We have found that the Adam optimizer works well for this purpose. We run the optimizer for 10,000 steps:
opt_pars, svi_results = model.optimize(
train_data,
rng_key=jax.random.PRNGKey(112358),
optimizer=numpyro.optim.Adam(1e-3),
num_steps=10_000,
svi_run_kwargs={"progress_bar": False},
)
svi_results.losses.block_until_ready()
Array([95983238.53252813, 95823005.32788713, 95664090.09020281, ...,
-101435.0993393 , -101435.09806804, -101435.09652145], dtype=float64)
Let’s check the loss trajectory for the last 1000 steps to see if (visually) the optimization has converged:
plt.plot(svi_results.losses[-1000:])
[<matplotlib.lines.Line2D at 0x7fc0d0352930>]
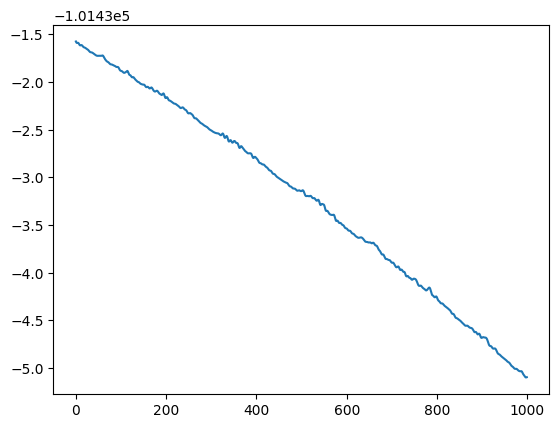
The loss is still decreasing, but much slower than in the first epochs. We therefore might want to run the optimizer for more steps, but for this demonstration, we will proceed with the current optimization.
We now have optimized linear transformation matrices and latent vectors for the training data:
opt_pars["label"], opt_pars["flux"]
({'data': {'A': Array([[ 0.36319401, -0.50868993, -0.54330448, -0.53844069, -0.62201603,
-0.47524558, 0.57888678, 0.54904651],
[-0.98748135, -1.16922188, -0.15258215, 0.93525579, -0.71824152,
-0.16683615, -0.625666 , -0.11217542]], dtype=float64)},
'err': {}},
{'data': {'A': Array([[ 0.29674488, 0.40541224, 0.12787881, ..., -2.96940962,
-0.17426367, -0.95109078],
[-0.46409794, -0.33296574, 1.59831767, ..., 0.24931179,
2.0018208 , 0.41430524],
[-0.72306828, -1.29123765, 0.59412217, ..., 0.55947244,
-0.28855843, 0.69923915],
...,
[ 2.13080207, 0.50043015, 1.04148304, ..., -1.11266423,
-0.32318338, 0.33986338],
[-1.04989179, 0.6235919 , -0.25739713, ..., -2.39233102,
-0.05479278, -0.97740279],
[ 0.30440012, -0.87427098, 0.77828418, ..., -2.27070777,
0.89697345, 0.4931043 ]], dtype=float64)},
'err': {}})
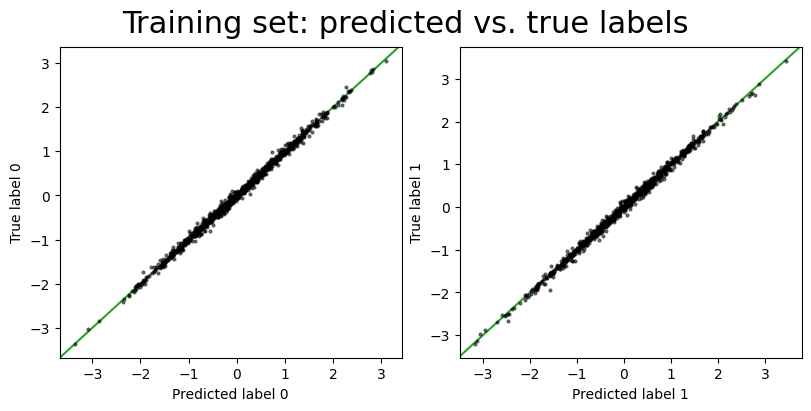
As we saw above, we can use the predict_outputs() method to generate predictions for the training data given the optimized latent vectors:
predict_train_values = model.predict_outputs(opt_pars["latents"], opt_pars)
pt_style = {"ls": "none", "ms": 2.0, "alpha": 0.5, "marker": "o", "color": "k"}
fig, axes = plt.subplots(1, 2, figsize=(8, 4), layout="constrained")
for i in range(predict_train_values["label"].shape[1]):
axes[i].plot(
predict_train_values["label"][:, i], train_data["label"].data[:, i], **pt_style
)
axes[i].set(xlabel=f"Predicted label {i}", ylabel=f"True label {i}")
axes[i].axline([0, 0], slope=1, color="tab:green", zorder=-100)
_ = fig.suptitle("Training set: predicted vs. true labels", fontsize=22)
# Pick some random pixel values to compare:
pixel_idx = np.array([9, 49, 55, 80])
fig, axes = plt.subplots(
1, len(pixel_idx), figsize=(4 * len(pixel_idx), 4), layout="constrained"
)
for i, j in enumerate(pixel_idx):
axes[i].plot(
predict_train_values["flux"][:, j], train_data["flux"].data[:, j], **pt_style
)
axes[i].set(xlabel=f"Predicted flux {j}", ylabel=f"True flux {j}")
axes[i].axline([0, 0], slope=1, color="tab:green", zorder=-100)
_ = fig.suptitle(
f"Training set: predicted vs. true flux ({len(pixel_idx)} random pixels)",
fontsize=22,
)
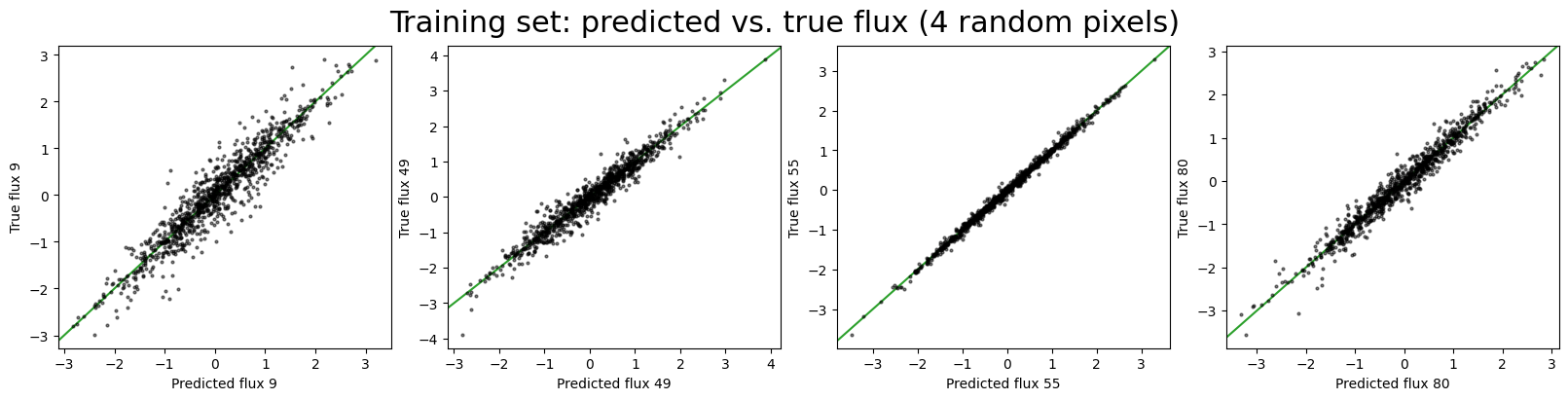
Both the predicted training set labels and fluxes look reasonable, which is a good sign that the model has learned the structure of the data. However, we also want to evaluate the model on the test data, which the model has not seen during optimization.
Optimize for latents for test set#
To predict labels and fluxes for the test set, we need to optimize the latent vectors for the test set. When we do this, we want to hold fixed the linear transformation matrices we learned from the training set data. We can do this using the optimize() method using the fixed_pars argument to specify values to fix a subset of the model parameters. In this case, we will fix the linear transformation matrices to the values we learned from the training set data:
fixed_pars = {
"label": {"data": {"A": opt_pars["label"]["data"]["A"]}},
"flux": {"data": {"A": opt_pars["flux"]["data"]["A"]}},
}
Now, when we run the optimizer, it will only optimize the latent vectors for the test set data:
test_opt_pars, test_svi_results = model.optimize(
test_data,
rng_key=jax.random.PRNGKey(12345),
optimizer=numpyro.optim.Adam(1e-3),
num_steps=10_000,
fixed_pars=fixed_pars,
svi_run_kwargs={"progress_bar": False},
)
test_svi_results.losses.block_until_ready()
Array([ 1.29648983e+08, 1.29021143e+08, 1.28395760e+08, ...,
-9.97525169e+04, -9.97525112e+04, -9.97525086e+04], dtype=float64)
Now, the outputted optimized parameters only contains the latent vectors for the test set data:
test_opt_pars
{'latents': Array([[-1.19481588e-01, 1.04694263e+00, 1.01398789e+00, ...,
8.66389858e-01, -7.02627824e-01, -4.52962574e-01],
[ 5.86136303e-01, 6.45070434e-01, -1.82490488e-01, ...,
1.45770523e-01, -3.85073870e-01, 1.82633070e-02],
[-4.81742810e-01, -5.82101835e-01, -1.75764095e-01, ...,
8.41655992e-02, -1.71558528e-01, -3.45771346e-01],
...,
[-1.83411627e-01, -6.36088741e-01, -1.45202146e-02, ...,
2.34029095e-02, -6.04776738e-01, 6.24864736e-02],
[-8.69576803e-04, -3.88195324e-02, 5.21883410e-01, ...,
-1.39766940e-01, 4.96386641e-02, -3.43110257e-02],
[-2.23185744e-01, -5.31224102e-01, 2.99946606e-01, ...,
-1.86749241e-01, -3.89710394e-01, -3.61438518e-01]], dtype=float64)}
test_opt_pars["latents"].shape
(1024, 8)
We can then use these latent vectors with the linear transformation matrices we learned from the training set data to generate predictions for the test set data:
predict_test_values = model.predict_outputs(test_opt_pars["latents"], fixed_pars)
fig, axes = plt.subplots(1, 2, figsize=(8, 4), layout="constrained")
for i in range(predict_test_values["label"].shape[1]):
axes[i].plot(
predict_test_values["label"][:, i], test_data["label"].data[:, i], **pt_style
)
axes[i].set(xlabel=f"Predicted label {i}", ylabel=f"True label {i}")
axes[i].axline([0, 0], slope=1, color="tab:green", zorder=-100)
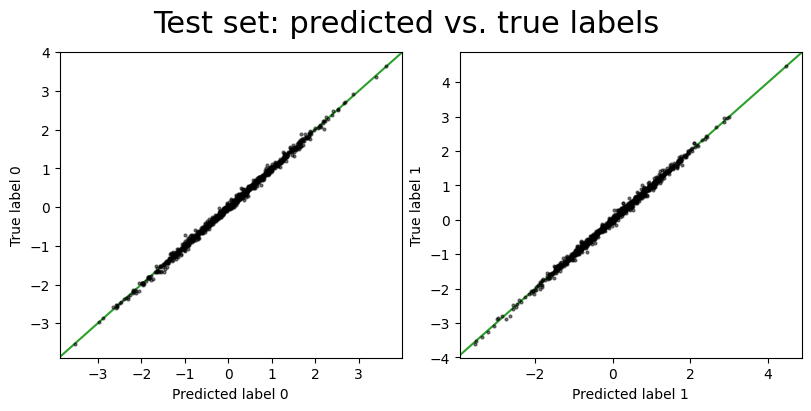
_ = fig.suptitle("Test set: predicted vs. true labels", fontsize=22)
fig, axes = plt.subplots(
1, len(pixel_idx), figsize=(4 * len(pixel_idx), 4), layout="constrained"
)
for i, j in enumerate(pixel_idx):
axes[i].plot(
predict_test_values["flux"][:, j], test_data["flux"].data[:, j], **pt_style
)
axes[i].set(xlabel=f"Predicted flux {j}", ylabel=f"True flux {j}")
axes[i].axline([0, 0], slope=1, color="tab:green", zorder=-100)
_ = fig.suptitle(
f"Test set: predicted vs. true flux ({len(pixel_idx)} random pixels)",
fontsize=22,
)
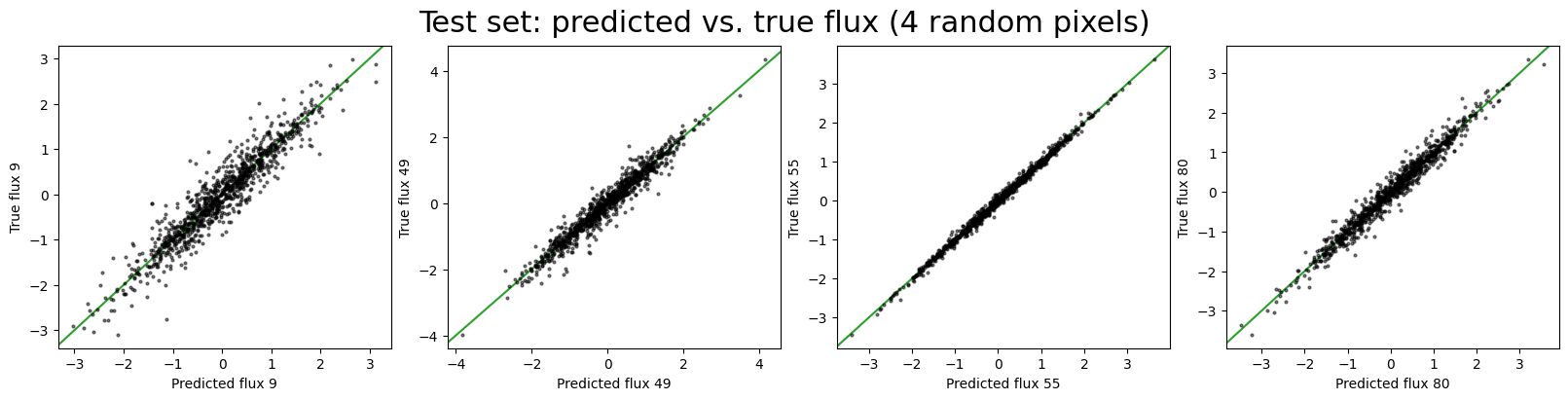
Good, the model still seems to be working well on the test set data. We can now quantitatively evaluate the model performance by comparing the predicted labels and spectra with the true values.
The raw, predicted labels and spectra are in the pre-processed domain, so we need to apply the inverse transform of the pre-processors to get the predicted labels and spectra in the original data domain (to compare to the true data):
predict_test_unprocessed = test_data.unprocess(predict_test_values)
The prediction error for the labels:
np.std(predict_test_unprocessed["label"].data - truth["label"][n_stars // 2 :], axis=0)
Array([0.005161 , 0.00948621], dtype=float64)
And the mean prediction error for the fluxes (across all pixels):
np.mean(
np.std(
predict_test_unprocessed["flux"].data - truth["flux"][n_stars // 2 :], axis=0
)
)
Array(0.00893876, dtype=float64)
Optimize for latents with partial data#
In real world cases with spectroscopic data, we will likely want to instead use the model to predict labels for sources that only have spectra and not labels. In this case, we can optimize the latent vectors for the test set data using only the spectra and not the labels. We can do this by now also specifying the names argument to the optimize() method to specify what output (and therefore data) blocks to use during optimization. In this case, we will specify only the flux name:
flux_only_data = plx.data.PolluxData(flux=test_data["flux"])
test_opt_pars_flux, _ = model.optimize(
flux_only_data,
rng_key=jax.random.PRNGKey(12345),
optimizer=numpyro.optim.Adam(1e-3),
num_steps=10_000,
fixed_pars=fixed_pars,
names=["flux"],
svi_run_kwargs={"progress_bar": False},
)
predict_test_values_flux = model.predict_outputs(
test_opt_pars_flux["latents"], opt_pars
)
predict_test_unprocessed_flux = test_data.unprocess(predict_test_values_flux)
We now have optimized latent vectors for the test set data using only the spectral flux data. We can now compare the predict labels with the true labels:
fig, axes = plt.subplots(1, 2, figsize=(8, 4), layout="constrained")
for i in range(predict_test_values_flux["label"].shape[1]):
axes[i].plot(
predict_test_values_flux["label"][:, i],
test_data["label"].data[:, i],
**pt_style,
)
axes[i].set(xlabel=f"Predicted label {i}", ylabel=f"True label {i}")
axes[i].axline([0, 0], slope=1, color="tab:green", zorder=-100)
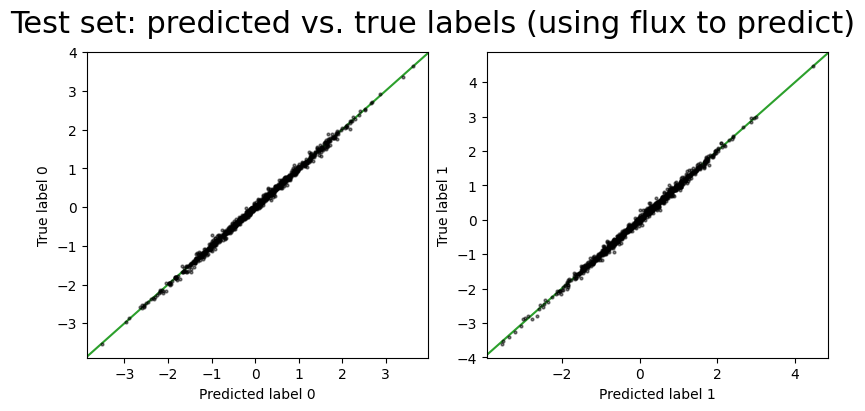
_ = fig.suptitle(
"Test set: predicted vs. true labels (using flux to predict)", fontsize=22
)
np.std(
predict_test_unprocessed_flux["label"].data - truth["label"][n_stars // 2 :], axis=0
)
Array([0.00520159, 0.00986082], dtype=float64)
Compared to the case above where we used both the labels and spectra to optimize the latent vectors for the test set, the prediction error is slightly higher when using only the spectra, as we would expect: the model has less information to constrain the latent vectors.
Conclusion#
This concludes this first tutorial on using the LuxModel class to define a Lux model with two linear outputs. We have demonstrated how to define the model, optimize the parameters, and evaluate the model performance on test data. Many aspects of the model structure and how the model is used are customizable, as described in the Lux paper. For example, we can use different (more complex) transformations that map the latent vectors to outputs (e.g., Gaussian process or multi-layer perceptron), or we could use the model in a probabilistic context to perform the train/test application in a single hierarchical inference. We hope to explore these extensions in future tutorials (contributions are welcome!).